Statistisk felmarginal |
| Svar |
Antal |
Andel |
| Ja |
460 |
46 % |
| Nej |
430 |
43 % |
| Vet ej |
110 |
11 % |
Enligt vår undersökning skulle andelen svenskar som säger nej till EMU vara 43%. Hur stort förtroende kan vi ha för detta resultat?
Även om det inte finns något bortfall denna gång och vi förutsätter att rena felräkningar inte förekommer, så finns det säkert ett visst slumpmässigt fel, som beror på det urval vi gjort.
Rent teoretiskt kan vi ha råkat fråga de 430 enda nejsägarna i Sverige. Sannolikheten för något sådant är oerhört liten och den går att beräkna.
Man kan alltså beräkna sannolikheten för att antalet nejsägare i Sverige till exempel är 53 %, det vill säga att vårt resultat är 10 % fel.
Det mest praktiska och allra vanligaste är att man, med en relativt enkel formel, beräknar svaret på följande fråga:
Vilken felmarginal måste jag acceptera om jag vill att det rätta värdet med en viss säkerhet ska ligga inom felmarginalen?
Svaret på denna fråga ges av följande formel, som med 95-procentig säkerhet ger en felmarginal i procent:
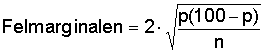
p = relativa frekvensen i procent
n = antalet observationer (storleken av stickprovet)
I vårt exempel är p = 43 % och n = 1000, som ger
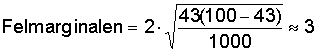
Det korrekta värdet ligger med 95 % sannolikhet inom intervallet 43 % ± 3 %, alltså mellan 40 % och 46 %. Man säger att detta är ett 95-procentigt konfidensintervall.
Ofta säger man också enklare: Den statistiska felmarginalen är 3 %.
Med samma formel får vi för övriga resultat:
| Svar |
Antal |
Andel |
Felmarginal |
| Ja |
460 |
46 % |
±3 % |
| Nej |
430 |
43 % |
±3 % |
| Vet ej |
110 |
11 % |
±2 % |
![]()